
Assessment Analytics Dashboard
Case Study Summary
The Assessment Analytics Dashboard project had been going on for a few months before I was brought on to conduct usability tests on the first round of designs.
My initial usability/discovery interviews illuminated major opportunities for improvement that the team was not aware of up until that point.
After delivering the findings, the team was able to quickly make edits to the designs based on my recommendations, which I then tested to validate.
Ultimately, by including user feedback into the design process, we were able to deliver a more useful and usable product to our consultants right out of the gate.
Make sure to read to the end to see a user’s first impressions of these research driven improvements…
Background
One of the services that Korn Ferry offers is a set of self assessments, much like the Myers Briggs personality test, but instead of focusing on personality, it focuses on the user’s professional competencies like collaboration, persuasion or decisiveness.
Typically, Korn Ferry consultants use these results to help participants develop professionally. On the aggregate level though, client leadership can use group assessment results to learn more about their organization as a whole.
The Assessment Analytics Dashboard allows Korn Ferry consultants and client leadership to view group trends in their organization, which can inform decisions like succession planning, leadership development and training opportunities.
The Product
The Team
My Role: User Researcher
Project Manager: Meera Butler
Design Manager: Liz Maloney
UX Designer: Elisabeth Parker
Visual Designer: Himanshu Guliya
Lead Developer: Kishor Nadgauda
Starting From The Beginning
Getting acquainted with the product
Before joining the team, the project had already gone through concept commit and a first round of designs had been made.
The solution was simple. Users select a subset of their organization and we display the group average for each “competency” that the assessment tracks. Competencies can be things like “collaborates,” “drives results,” or “optimizes work processes” etc…
Users can then filter down the results based on job function, job level or location. One primary use case for this tool is to compare the results of one participant to the results of a larger group. i.e. How does John Doe stack up against the rest of the sales team?
Preparing for usability/discovery interviews
Before starting on scripts or prototyping, I scheduled 1:1 meetings with the UX Designer and Project Manager on the team. This allowed me to identify any outstanding questions that they had, as well as get clarification on any questions I had.
These meetings also functioned as brainstorming sessions to generate as many questions as possible, which I then paired down into a usability testing script and prototype shown to the left.
Running the usability/discovery interviews
I targeted one main user group being Korn Ferry consultants. I elected not to interview client users at this time because, for MVP, it was consultant use only and consultants are generally more familiar with the processes, deliverables and variety of use cases available.
I interviewed five consultants who will be using this dashboard once it’s complete. I had them walk through the prototype, gathering their first impressions and asking follow up questions to better understand their needs when analyzing group assessment data.

Gathering Top Findings
What is Mission Critical?
My favorite moment from these interviews is when a consultant asked “well this is all fine and good, but how do I tell which competencies are mission critical?” Mission critical? I thought to myself, what’s that?
Apparently, during engagements with our clients, consultants will choose roughly 10 competencies to be considered “mission critical,” meaning they are the most important for developmental insights.
I probed further to discover that many consultants will look at only the mission critical competencies and ignore the rest. This means that if we aren’t displaying what is mission critical, we are missing the mark.

Sorting or “Stacked Rank”
It became apparent that the data we are displaying only becomes relevant when identifying an organization’s strongest or weakest competencies. Therefore the most important values are the highest and lowest scores. This sentiment was reflected in examples the consultants shared with me (shown left,) where they would remove everything but the top and bottom scores.
As it stood, we were not providing an easy way to identify the highest and lowest scores outside of going through the graphs with a fine tooth comb.

Preferred Data Visualization
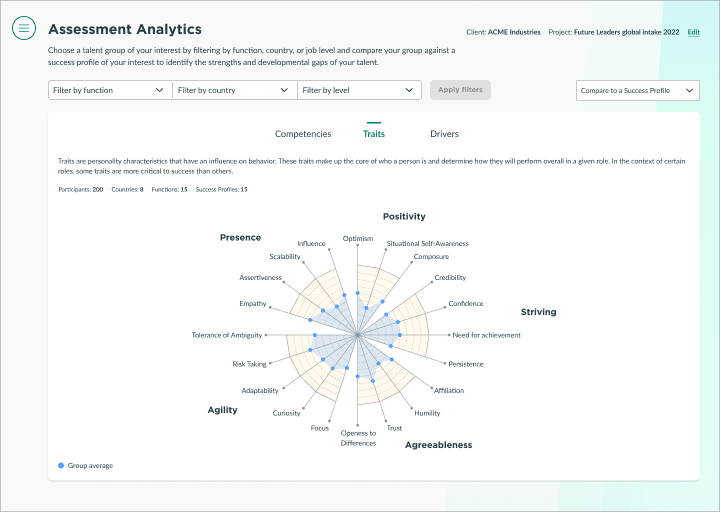
When we reached the graph for Traits (shown right) one consultant said “I can’t stand this graph.” What they were referring to was that Traits is displayed as a spider graph, which can be difficult to interpret.
They said that the spider graph is good for doing work with an individual so it makes sense that the pattern was retained when moving to group data. The issue is that, when analyzing group data, differences are often very small and a spider graph is not the right type of graph for perceiving small differences.
Below are three examples of opportunities for improvement that I uncovered during the study. There, of course, were other findings, but I chose these for their visual and functional implicaitons.
Delivering Recommendations
Synthesizing Findings
For this round of research (and most research I conduct) I used a note taking method that utilizes FigJam. Shown to the right is an example - I write the questions in a column of purple stickies and then take notes by adding stickies to the right, each sticky being an answer or quote.
Doing this allows me to immediately break into affinity mapping once the interviews are complete. Shown here, I first categorized the stickies by an overarching theme and then stacked them to show saturation.
Presenting To Stakeholders
I took the most common themes and delivered them in a presentation to stakeholders, which included the entire team for this project, as well as some company leadership interested in the results.
To give an example of my process - in my research presentations, a strategy I often use, is to deliver recommendations alongside findings, instead of at the very end. This keeps a cadence of “I found that users X, which causes Y, and therefore we should Z.”
Prioritizing stories
After presenting the findings to the larger group, I ran a workshop with the project manager and UX designer. Together, we aligned on the most effective way to deliver recommendations as Jira tickets.
The workshop consisted of determining where the research epic should be in the Jira, what the tickets should be labeled as, and what the format should be for writing stories. Then, we went through a confluence of all the findings and gave each one a priority, a status and an assignee. These tickets were then put into upcoming sprints.
Developing Solutions
Working With A Cross Functional Team

After handing off my recommendations in the form of Jira tickets, much of my work was done. This is a good opportunity for me to show my appreciation for the rest of the team that tackled this project.
The project manager, Meera, drove these stories in the sprints, the UX designer, Elisabeth, used a collaborative approach of problem solving, and the visual designer Himanshu took our ideas over the finish line.
At this stage, I acted mostly in an advisory role so that everyone could make sure our solutions were meeting our user’s expectations.
Best Practice Research: Complex Filtering Patterns

A unique issue came up while working on our design improvements: Too many filters! Between my recommendations and an upcoming roadmap item, it became apparent that we would quickly run out of space on the dashboard with all the necessary filters and tools.
I was tasked with researching best practices for handling complex filtering patterns. The solution I delivered to the team was to have a separate screen/modal/panel for filtering. Accessed through an edit button, the filtering screen allows user to take complex actions on a various widget, without cluttering the dashboard as a whole.
Best Practice Research: Graphs with too much data
Another finding I did not mention earlier was that users sometimes need to view all the data in one large group, not divided into the categories shown in previous designs. This presents an issue where data overflows past the fold, which puts the scale below the fold as well, making it harder to interpret the data.
After some quick research, I discovered that the best practices for handling this is to make the graph’s window static on the page, and give a scrollbar inside the window to access data further down.

Validating Design Decisions
Translating Research Into Designs
Shown to the right are some examples of how research impacted design. Each of the data visualization methods shown can be linked to a finding that I have outlined earlier in this case study.
Top Left: Mission critical competencies shown with benchmarks.
Top right: All competencies shown with scrollbar.
Bottom left: Only mission critical sorted in descending order.
Bottom right: Traits shown as a bar graph instead of a spider graph.

Testing Solutions
Once the designs were updated to reflect all of the feedback gathered from the first round of research, they were ready to be tested again to validate that they would meet our user’s expectations.
Additionally, these interviews were used as discovery for upcoming features that were on the roadmap. Our users are often extremely busy, so whenever I have the opportunity to talk with them, I make sure to cover a wide range of topics, on top of doing a usability test.

Repeating The Process
Overall, (as you will see in the video below) our designs were received positively. Still, there are always opportunities for improvement. Some examples of recommendations from the second round of research are:
The sort function needed to extend to the “categorized” view.
Users expected to be able to view participant distribution within each competency. ie: “the top 25% of participants scored within X range.”
Values should be displayed statically to clarify on small differences.
These findings then follow the same process as outlined in this case study, as we continue to iterate and improve on our product.
Conclusion
Reflecting On The Experience
Thank you for reading through this case study. I hope you agree that the processes of this test exemplify good UX research practices.
To conclude - one question I struggle with is; How do we convey or quantify a user’s “delight” when using a product? How can we capture the “sparks joy” moment? - I think that this compilation of one consultant reacting to our designs does a good job of doing this…